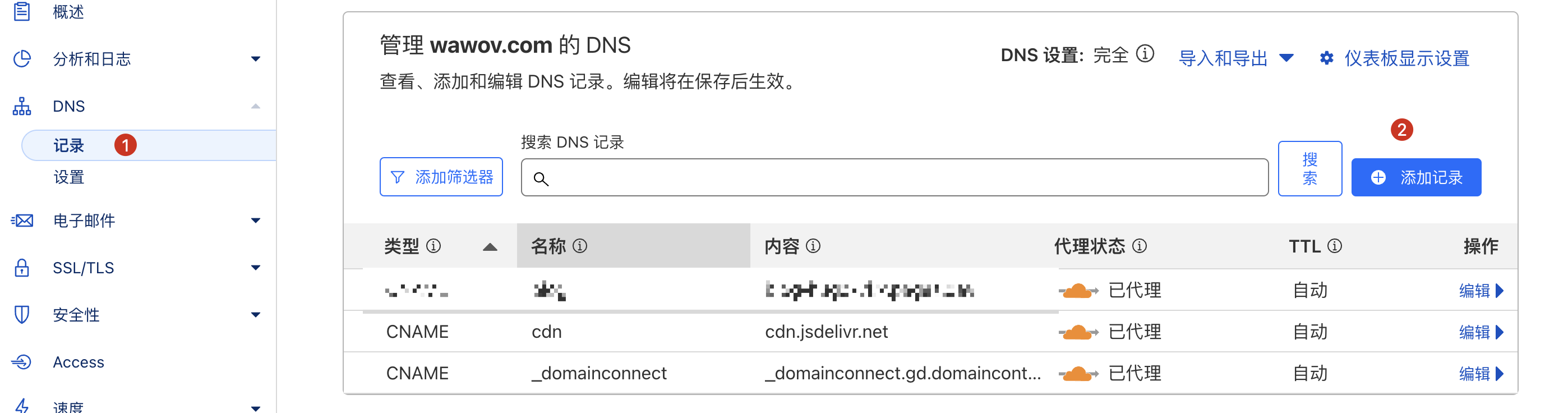
mac上使用homebrew安装,
brew install protobuf
其他os,可以到官网下载。
编写.proto文件
列子:
package pingan.kanyun.sdk;
option java_package = "com.pingan.kanyun.sdk.proto";
message DeviceInfo{
optional string os_version = 1;//OS版本,
optional string app_version = 2;//APP版本,
optional string imei_meid = 3;//机器码(IMEI/MEID),
optional string bandName = 4;//客户端品牌信息
optional string model = 5;//手机型号
optional string cpuModel = 6;//CPU型号
optional string cpuInstructionSet = 7;//CPU指令集
optional string cpuHardware = 8;//CPU厂商
optional bool isRoot = 9;//是否越狱
optional string displaySize = 10;//屏幕分辨率
optional string language = 11;//语言
optional int32 result_per_page = 12;
repeated int32 samples = 13 [packed=true];
enum PhoneType{
MOBILE = 0;
HOME = 1;
WORK = 2;
}
}
message定义了11个field,每个field都有名称与类型组成。
可以是基本类型:string int32,也可以是指定的复杂类型属性,包括枚举和其他类型
每一个field都是唯一数字的标记,这是用来标记这个field在message二进制格式中的位置,一旦使用就不能在修改顺序
ps:
-
标记从1-15只有一个字节编码,包括自增长属性
-
标记从16-2047占用两个字节。因此尽量频繁使用1-15,记住为未来的扩展留下一些位置。
-
最小的tag你可以定义为1,最大2的29次方-1 536870922.你同样不能使用19000-19999(这个位置已经被Google PB实现)
-
由于历史原因,repeated字段如果是基本数字类型的话,不能有效地编码。现在代码可以使用特殊选项[packed=true]来得到更有效率的编码。
如果字段的属性值是固定的几个值,可以使用枚举
Enumerations
message SearchRequest {
required string query = 1;
optional int32 page_number = 2;
optional int32 result_per_page = 3 [default = 10];
enum Corpus {
UNIVERSAL = 0;
WEB = 1;
IMAGES = 2;
LOCAL = 3;
NEWS = 4;
PRODUCTS = 5;
VIDEO = 6;
}
optional Corpus corpus = 4 [default = WEB];
}
自定义消息类型
message SearchResponse {
repeated Result result = 1;
}
message Result {
required string url = 1;
optional string title = 2;
repeated string snippets = 3;
}
import 定义
使用import关键字,可以引用另外一个.proto文件
import "myproject/other_protos.proto";
内部类
message SearchResponse {
message Result {
required string url = 1;
optional string title = 2;
repeated string snippets = 3;
}
repeated Result result = 1;
}
引用内部类是,使用parent.type,例如:
message SomeOtherMessage {
optional SearchResponse.Result result = 1;
}
Extentions
extensions 声明一个消息中的一定范围的field的顺序数字用于进行扩展。其它人可以在自己的.proto文件中重新定义这些消息field,而不需要去修改原始的.proto文件
message Foo{
extentions 100 to 199;//这说明100~199是保留的。
}
在新的fields添加Foo
extend Foo {
optional int32 bar = 126;
}
内嵌的extensions
message Baz {
extend Foo {
optional int32 bar = 126;
}
}
选择Extension 顺序数字
非常重要的一点是双方不能使用同样数字添加一样的message类型,这样extension会被解释为错误类型。
Packages
可以给一个.protol文件增加一个optional的package描述,来保证message尽量不会出现名字相同的重名。
package会根据选择的语言来生成不同的代码。
package foo.bar;
message Open {
}
package会根据选择的语言来生成不同的代码:
生成的classes是用C++的namespace来区分的。举例:Open would be in the namespace foo::bar。
package用于Java的package,除非你单独的指定一个option java_package 在.proto文件中。
package是被忽略的,因为Python的modules是通过它们的文件位置来组织的。
options
在一个proto文件中,还可以存在一些options。options不能改变一个声明的整体的意义,但是可以影响一定的上下文。
-
一些options是第一级的,意味着它们应该被写在顶级范围,而不是在任何message,enum,sercie的定义中。
-
一些options是message级别的,意味着它们应该被写入message的描述中。
-
一些options是field-level级别的,意味着它们应该被写入field的描述中,options也可以被写入enum类型中,enum的值,service类型 和service方法。
常用的options:
- java_package (file option)
定义生成的java class的package。如果在proto文件中没有明确的java_package选项,那么默认会使用package关键字指定的package名。
但是proto package通常不会好于Java packages,因为proto packages通常不会以domain名称开始。
如果不生成java代码,此选项没有任何影响。
例子:
option java_package = "com.example.foo";
- java_outer_classname (file option)
指定想要生成的class名称,如果此参数没有指定的话,那么默认使用.proto文件名来做为类名,并且采用驼峰表示(比如:foo_bar.proto 为 FooBar.java)
如果不生成java代码,此选项没有影响。
例子:
option java_outer_classname = "Ponycopter";
- optimize_for (file option)
可以设置为speed、code_size或者lite_runtime。
-
SPEED:默认。protocol编译器会生成classes代码,提供了message类的序列化、转换和其它通用操作。这个代码是被高度优化过的。
-
CODE_SIZE: protocol编译器会生成最小的classes,并且依赖共享、基于反射的代码实现序列化、转换和其它通用操作。生成的classes代码小于speed,但是操作会慢一点。classes会实现跟SPEED模式一样的公共API。这个模式通常用在一个应用程序包含了大量的proto文件,但是并不需要所有的代码都执行得很快
-
LITE_RUNTIME: protocol编译器会生成仅仅依赖 lite 运行库(libprotobuf-lite代替libprotobuf)。lite运行时比全量库小很多,省略了某种特性(如: descriptors and reflection)这个选项对于运行在像移动手机这种有约束平台上的应用更有效。 编译器仍然会对所有方法生成非常快的代码实现,就像SPEED模式一样。protocol编译器会用各种语言来实现MessageList接口,但是这个接口仅仅提供了其它模式实现的Message接口的一部分方法子集。
例子:
option optimize_for = CODE_SIZE;
- cc_generic_services, java_generic_services, py_generic_services (file options)
无论如何,protoc编译器会生成基于C++,Java,Python的抽象service代码,这些默认都是true。截至到2.3.0版本,RPC实现提供了代码生成插件去生成代码,不再使用抽象类。
option cc_generic_services = false;
option java_generic_services = false;
option py_generic_services = false;
- message_set_wire_format (message option)
如果设置为true,消息使用不同的二进制格式来兼容谷歌内部使用的称为MessageSet的旧格式。用户在google以外使用,将不再需要使用这个option。
消息必须按照以下声明:
message Foo {
option message_set_wire_format = true;
extensions 4 to max;
}
protocol buffer还允许你自定义options。这是个高级特性,大多数人并不需要。options其实都定义在 google/protobuf/descriptor.proto文件中。
自定义的options是简单的,继承这些messages:
import "google/protobuf/descriptor.proto";
extend google.protobuf.MessageOptions {
optional string my_option = 51234;
}
message MyMessage {
option (my_option) = "Hello world!";
}
这里我们定义了一个message级别的消息选项,当使用这个options的时候,选项的名称必须用括号括起来,以表明它是一个extension。
我们在C++中读取my_option的值就像下面这样:
string value = MyMessage::descriptor()->options().GetExtension(my_option);
在Java中:
String value = MyProtoFile.MyMessage.getDescriptor().getOptions().getExtension(MyProtoFile.myOption);
为了生成java、python、C++代码,你需要运行protoc编译器 protoc 编译.proto文件。编译器运行命令:
protoc --proto_path=IMPORT_PATH --cpp_out=DST_DIR --java_out=DST_DIR --python_out=DST_DIR path/to/file.proto
使用.代表当前目录。
import_path 查找proto文件的目录,如果省略的话,就是当前目录。存在多个引入目录的话,可以使用--proto_path参数来多次指定,
-I=IMPORT_PATH就是--proto_path的缩写
输出目录
-
--cpp_out 生成C++代码在DST_DIR目录
-
--java_out 生成Java代码在DST_DIR目录
-
--python_out 生成Python代码在DST_DIR目录
有个额外的好处,如果DST是.zip或者.jar结尾,那么编译器将会按照给定名字输入到一个zip压缩格式的文件中。
输出到.jar会有一个jar指定的manifest文件。注意 如果输出文件已经存在,它将会被覆盖;编译器的智能不足以自动添加文件到一个存在的压缩文件中。
你必须提供一个或者多个.proto文件用作输入。虽然文件命名关联到当前路径,每个文件必须在import_path路径中一边编译器能规定它的规范名称。
更新message
如果一个message 不再满足所有需要,需要对字段进行调整。(举例:对message增加一个额外的字段,但是仍然有支持旧格式message的代码在运行)
要注意以下几点:
-
不要修改已经存在字段的数字顺序标示
-
可以增加optional或者repeated的新字段。这么做以后,所有通过旧格式message序列化的数据都可以通过新代码来生成对应的对象,正如他们不会丢失任何required元素。你应该为这些元素添加合理的默认值,以便新代码可以与旧代码生成的消息交互。 新代码创建的消息中旧代码不存在的字段,在解析的时候,旧代码会忽略掉新增的字段。无论如何,未知的field不会被丢弃,注意未知field对于Python来说当前不可用。
-
非required字段都可以转为extension ,反之亦然,只要type和number保持不变。
-
int32, uint32, int64, uint64, and bool 是全兼容的。这意味着你能改变一个field从这些类型中的一个改变为另一个,而不用考虑会打破向前、向后兼容性。如果一个数字是通过网络传输而来的相应类型转换,你将会遇到type在C++中遇到的问题。(e.g. if a 64-bit number is read as an int32, it will be truncated to 32 bits)
-
sint32 and sint64 彼此兼容,但是不能兼容其它integer类型。
-
string and bytes 在UTF-8编码下是兼容的。
-
如果bytes包含一个message的编码,内嵌message与bytes兼容。
-
fixed32 兼容 sfixed32, fixed64 兼容 sfixed64。
-
optional 兼容 repeated。用一个repeat字段的编码结果作为输入,认为这个字段是可选择的客户端会这样处理,如果是原始类型的话,获得最后的输入作为相应的option值;如果是message 类型,合并所有输入元素。
-
更改默认值通常是OK的。要记得默认值并不会通过网络发送,如果一个程序接受一个特定字段没有设置值的消息,应用将会使用自己的版本协议定义的默认值,不会看见发送者的默认值。