Android webview交互性能监测指标获取方法
业界衡量移动web app交互性能的优劣主要是通过监测webview渲染页面时白屏时间,DOM树构建时间,整页时间和首屏时间这三个指标来完成的,那么这四个指标分别的意义是什么呢?我们从w3c提供的navigation Timing中看到交互性能指的是Processing和onLoad这两部分的时间。
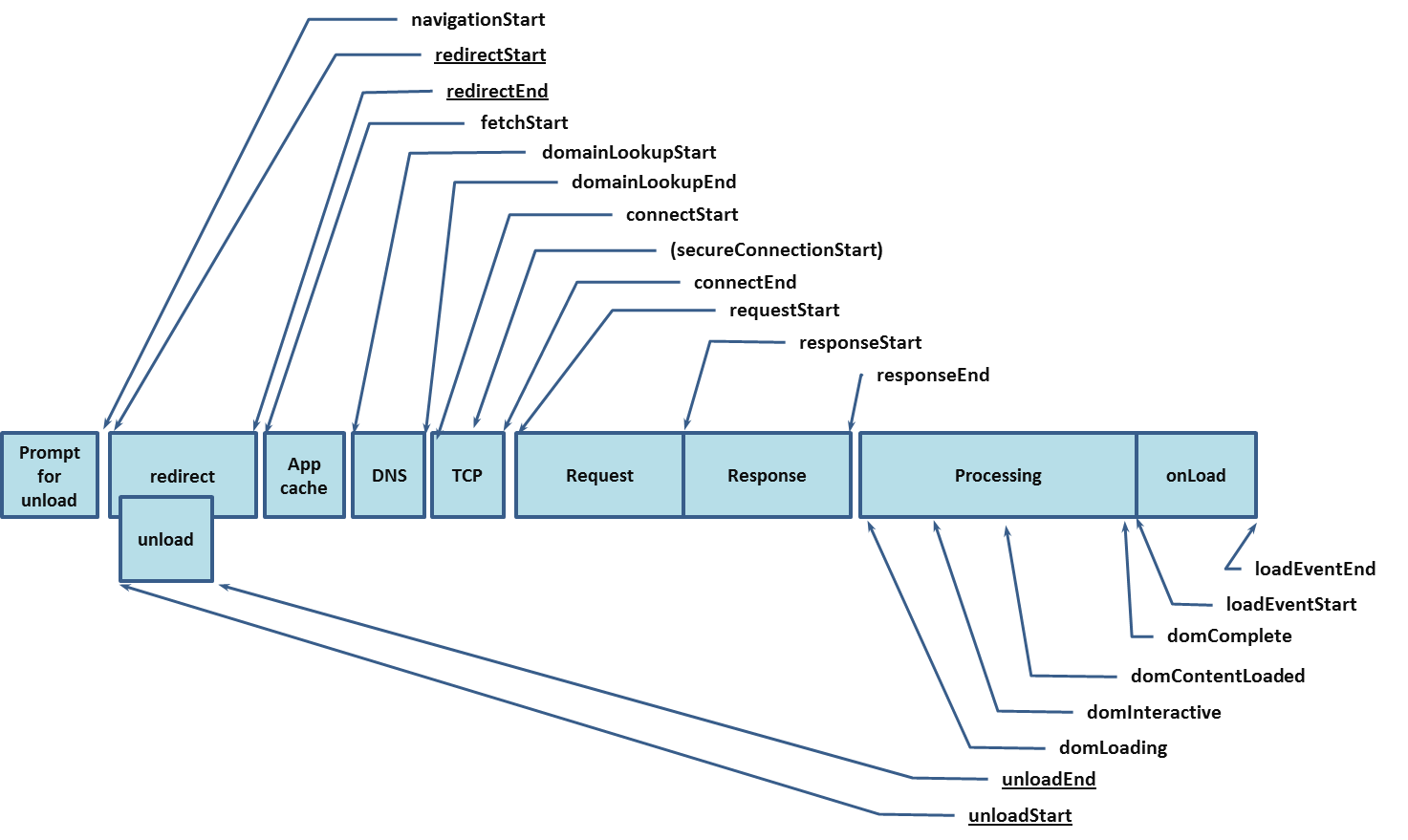
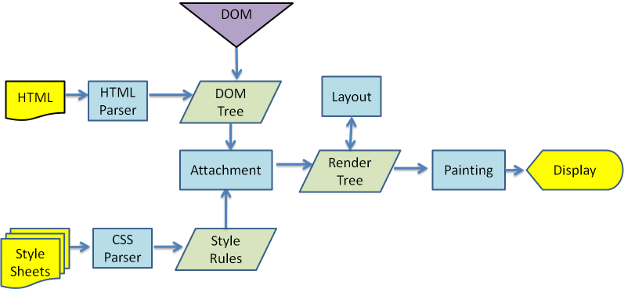
在浏览器交互阶段(Processing和onLoad时间段)浏览器接收服务器返回的基础页数据后,浏览器需要对HTML这个单纯的文本内容进行解析,从文本中构建出一个内部数据结构,叫做DOM树(DOM tree),用于组织将要绘制在屏幕上的内容。从HTML也能得到外联或内联的CSS脚本和JavaScript脚本,当然还有媒体文件,比如图片、视频、声音,这些都需要再次发起网络请求下载。CSS文本内容中的规则同样会被构建成一个内部数据结构,叫做CSS树(CSS tree),来决定DOM树的节点在屏幕上的布局、颜色、状态效果。JavaScript脚本被触发执行后,除了计算业务,往往还需要操作DOM树,就是所谓的DOM API。
-
白屏时间 ***指浏览器开始显示内容的时间。***但是在传统的采集方式里,是在HTML的head标签结尾里记录时间戳,来计算白屏时间。在这个时刻,浏览器开始解析body标签内的内容。而现代浏览器不会等待CSS树(所有CSS文件下载和解析完成)和DOM树(整个body标签解析完成)构建完成才开始绘制,而是马上开始显示中间结果。所以经常在低网速的环境中,观察到页面由上至下缓慢显示完,或者先显示文本内容后再重绘成带有格式的页面内容。在android中我们通过使用
webview.WebChromeClient的onReceivedTitle事件来近似获得白屏时间。 -
DOM树构建时间 指浏览器开始对基础页文本内容进行解析到从文本中构建出一个内部数据结构(DOM树)的时间,这个事件是从HTML中的onLoad的延伸而来的,当一个页面完成加载时,初始化脚本的方法是使用load事件,但这个类函数的缺点是仅在所有资源都完全加载后才被触发,这有时会导致比较严重的延迟,开发人员随后创建了domready事件,它在DOM加载之后及资源加载之前被触发。domready被众多JavaScript库所采用,它在本地浏览器中以
DOMContentLoaded事件的形式被使用。在android中我们通过注入js代码到webview中的方式来实现;具体实现上,在WebChromeClient的onReceivedTitle事件被触发时注入我们的js代码,然后通过WebChromeClient的onJsPrompt事件来获取domc(window.DOMContentLoaded事件)时间。
@Override
public void onReceivedTitle (WebView view, String title) {
view.loadUrl("javascript:" +
"window.addEventListener('DOMContentLoaded', function() {" +
"prompt('domc:' + new Date().getTime());" +
);
}
@Override
public boolean onJsPrompt(WebView view, String url, String message, String defaultValue, JsPromptResult r) {
Log.i(UAQ_WEB_ACTIVITY, "**** Blocking Javascript Prompt :" + message);
if(message != null){
if(!preCacheRun){
String[] strs = message.split(":");
if(2 == strs.length){
if("domc".equals(strs[0])){
result.getCurrentRun().setDocComplete(Long.valueOf(strs[1].trim()));
}
}
}
}
r.confirm(defaultValue);
return true;
}
- 首屏时间 指从网页应用的角度定义的指标,在Navigation Timing或者浏览器实现中并没有相关指标值。首屏时间,***是指用户看到第一屏,即整个网页顶部大小为当前窗口的区域,显示完整的时间。***常用的方法有,页面标签标记法、图像相似度比较法和首屏高度内图片加载法;
- 页面标签标记法,在HTML文档中对应首屏内容的标签结束位置,使用内联的JavaScript代码记录当前时间戳,比较局限;
- 图像相似度比较法,通过比较连续截屏图像的像素点变化趋势确定首屏时间,最为科学和直观的方式,但是比较消耗本地设备的运行资源;
- 首屏高度内图片加载法,通过寻找首屏区域内的所有图片,计算它们加载完的时间去得到首屏时间,这样比较符合网页的实际体验并且比较节省设备运行资源;
具体实现上我采用的是最后一种,即"首屏高度内图片加载法";因为通常需要考虑首屏时间的页面,都是因为在首屏位置内放入了较多的图片资源。现代浏览器处理图片资源时是异步的,会先将图片长宽应用于页面排版,然后随着收到图片数据由上至下绘制显示的。并且浏览器对每个页面的TCP连接数限制,使得并不是所有图片都能立刻开始下载和显示。因此我们在DOM树构建完成后即可遍历获得所有在设备屏幕高度内的所有图片资源标签,在所有图片标签中添加document.onload事件,在整页加载完成(window.onLoad事件发生)时遍历图片标签并获得之前注册的document.onload事件时间的最大值,该最大值减去navigationStart即认为近似的首屏时间。在android中我们通过注入js代码到webview中的方式来实现;具体实现上,在WebChromeClient的onReceivedTitle事件被触发时注入我们的js代码,然后通过
WebChromeClient的onJsPrompt事件来获取firstscreen时间。
js部分计算首屏时间的逻辑代码:
function first_screen () {
var imgs = document.getElementsByTagName("img"), fs = +new Date;
var fsItems = [], that = this;
function getOffsetTop(elem) {
var top = 0;
top = window.pageYOffset ? window.pageYOffset : document.documentElement.scrollTop;
try{
top += elem.getBoundingClientRect().top;
}catch(e){
}finally{
return top;
}
}
var loadEvent = function() {
//gif避免
if (this.removeEventListener) {
this.removeEventListener("load", loadEvent, false);
}
fsItems.push({
img : this,
time : +new Date
});
}
for (var i = 0; i < imgs.length; i++) {
(function() {
var img = imgs[i];
if (img.addEventListener) {
!img.complete && img.addEventListener("load", loadEvent, false);
} else if (img.attachEvent) {
img.attachEvent("onreadystatechange", function() {
if (img.readyState == "complete") {
loadEvent.call(img, loadEvent);
}
});
}
})();
}
function firstscreen_time() {
var sh = document.documentElement.clientHeight;
for (var i = 0; i < fsItems.length; i++) {
var item = fsItems[i], img = item['img'], time = item['time'], top = getOffsetTop(img);
if (top > 0 && top < sh) {
fs = time > fs ? time : fs;
}
}
return fs;
}
window.addEventListener('load', function() {
prompt('firstscreen:' + firstscreen_time());
});
}
webview的注入代码:
private void registerOnLoadHandler(WebView view) {
String jscontent = getJavaScriptAsString();
view.loadUrl("javascript:" + jscontent +
"window.addEventListener('DOMContentLoaded', function() {" +
"first_screen();
});"
);
}
@Override
public void onReceivedTitle (WebView view, String title) {
registerOnLoadHandler(view);
}
@Override
public boolean onJsPrompt(WebView view, String url, String message, String defaultValue, JsPromptResult r) {
Log.i(UAQ_WEB_ACTIVITY, "**** Blocking Javascript Prompt :" + message);
if(message != null){
if(!preCacheRun){
String[] strs = message.split(":");
if(2 == strs.length){
if("firstscreen".equals(strs[0])){
result.getCurrentRun().setFirstScreen(Long.valueOf(strs[1].trim()));
}
}
}
}
r.confirm(defaultValue);
return true;
}
- 整页时间
***指页面完成整个加载过程的时刻。***从Navigation Timing API上采集,就是loadEventEnd减去navigationStart。在传统采集方法中,会使用window对象的onload事件来记录时间戳,它表示浏览器认定该页面已经载入完全了。android中我们通过注入js代码到webview中的方式来实现;具体实现上,在WebChromeClient的onReceivedTitle事件被触发时注入我们的js代码,然后通过
WebChromeClient的onJsPrompt事件来获取load(window.onLoad事件)时间。
@Override
public void onReceivedTitle (WebView view, String title) {
view.loadUrl("javascript:" +
"window.addEventListener('load', function() {" +
"prompt('load:' + new Date().getTime());" +
);
}
@Override
public boolean onJsPrompt(WebView view, String url, String message, String defaultValue, JsPromptResult r) {
Log.i(UAQ_WEB_ACTIVITY, "**** Blocking Javascript Prompt :" + message);
if(message != null){
if(!preCacheRun){
String[] strs = message.split(":");
if(2 == strs.length){
if("load".equals(strs[0])){
result.getCurrentRun().setFullyLoaded(Long.valueOf(strs[1].trim()));
}
}
}
}
r.confirm(defaultValue);
return true;
}